- Products
- -
- Starburst vs OSS Trino
- Open Data Lakehouse
- Data Mesh
- Artificial Intelligence
- ELT Data Processing
- Data Applications
- Data Migrations
- Data Products
- Customers
- -
- Learn
- -
- Partners
- -
- About
- -
- Login

- Start Free
Starburst Galaxy
Fully managed in the cloud
Starburst Enterprise
Self-managed anywhere
By Use Cases
By Industry
Documentation
Connect
Education
×
Blog
Resources
Pages
Documentation
Starburst Enterprise
It's decision time.
Starburst helps you make better decisions with fast access to all your data, without the complexity of data movement and copies.
We know the problem all too well
Your company has more data than ever before, but your data teams are stuck waiting to analyze it. Starburst unlocks access to data where it lives, no data movement required, giving your teams fast & accurate access to more data for analysis.
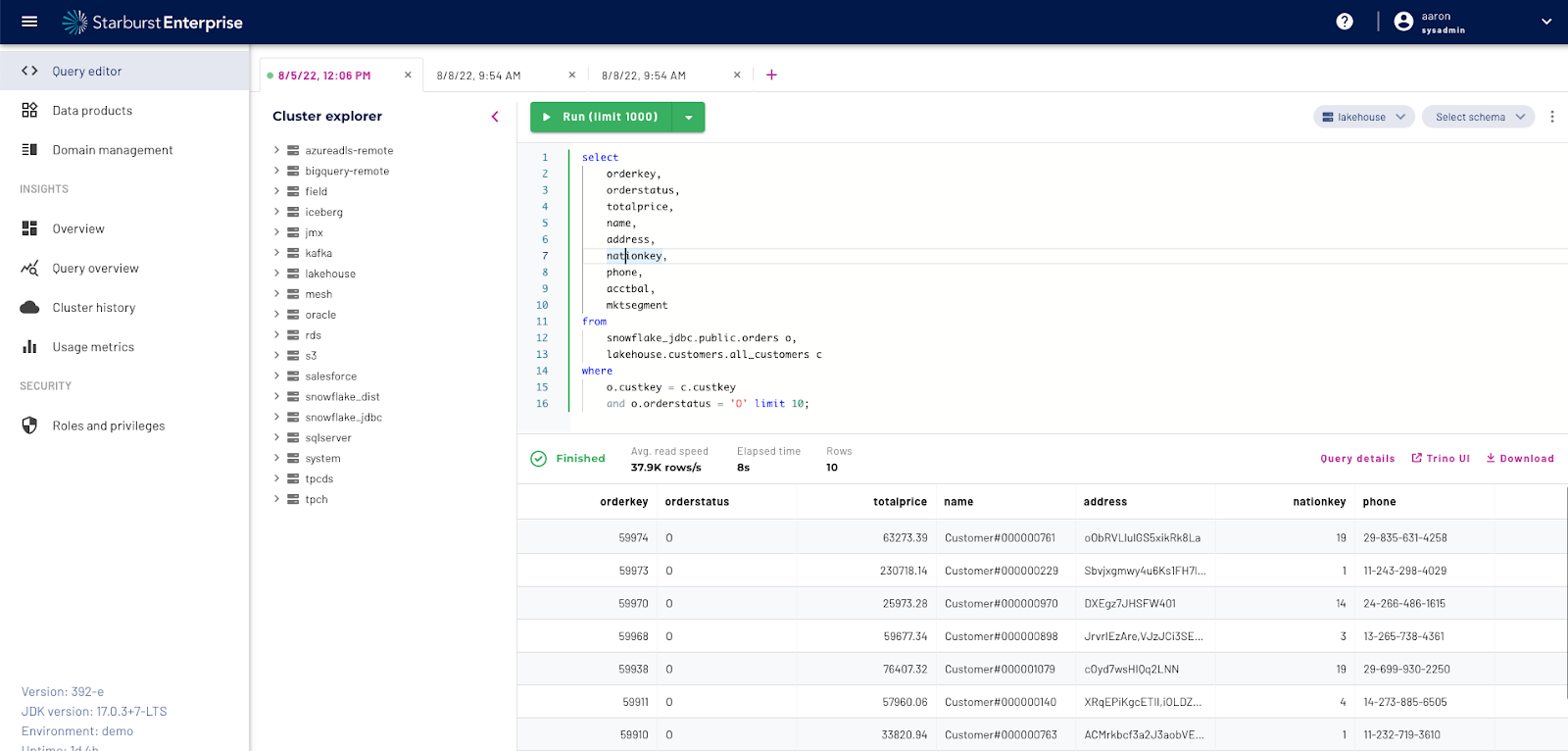
How it works
Starburst Enterprise is a fully supported, production-tested and enterprise-grade distribution of open source Trino (formerly Presto® SQL). It improves performance and security while making it easy to deploy, connect, and manage your Trino environment.
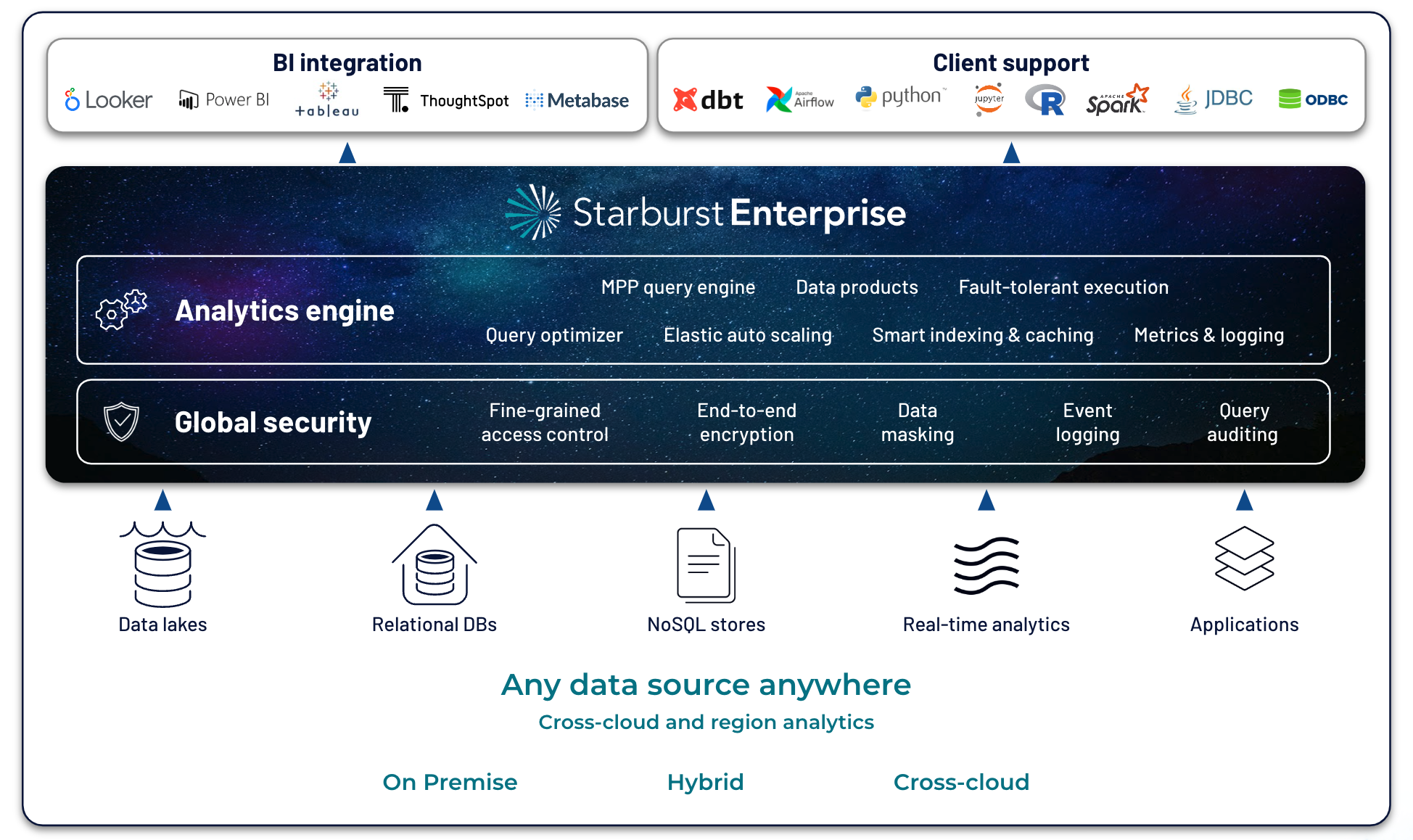
Through connecting to any source of data – whether it’s located on-premise, in the cloud, or across a hybrid cloud environment – Starburst lets your team use the analytics tools they already know & love while accessing data that lives anywhere.
Hundreds of customers love Starburst







Deploy anywhere
On-prem and/or any cloud, simultaneously connect to any infrastructure, today and tomorrow
Get started anywhereRobust ecosystem of advanced connectors
Live access to 50+ data sources including modern and legacy enterprise sources
Connect all your dataScalability
Leverage elastic cloud and on-prem compute resources to scale up or down to meet demand
Unlimited scaleEngine built for performance
MPP Query Engine built for speed and performance at scale
Recent performance benchmarkGlobal hybrid and cross-cloud analytics
Access data across boundaries, without the need to move it
Learn about StargateEase of use and consumability
Easy discovery and consumption of high-quality data
More on data productsSecurity and compliance
Centralized, fine-grained access and control to all your data
Secure everythingDomain expertise
From the Trino creators with proven experience deploying in the world's largest data
24x7, we've got your back
"To get this kind of information in the past would have involved several weeks of copying and analysing data. With EMIS-X Analytics, powered by Starburst Enterprise, researchers get the information in almost real-time."
Richard Jarvis
Chief Analytics Officer, EMIS Health
Full EMIS story
"The decision to deploy Starburst Enterprise was made simpler because it has proven to be a reliable, fast, and stable query engine for S3 data lakes."
Alberto Miorin
Engineering Lead, Zalando
Full Zalando story
"Starburst separates compute and storage, making it possible to scale economically and analyze 25PB of data— 100B rows of new data per day from 25+ sources."
Ivan Black
Director, FINRA
Full Finra storyDelivering value for your entire organization
Data engineering
Deploy and scale with ease
Elastic search
Ansible | Cluster auto scaling | KubernetesCost & performance optimized
MPP query engine | Dynamic filtering | CBOSecurity & compliance
RBAC | Query logs | Data maskingData science and analytics
Instant access to all your data
Data discoverability
Data products | Catalogs | ViewsIntuitive user experience
SQL editor | Insights UI | BI integrationsRich developer ecosystem
50+ connectors | Client integrationLine of business
Better decisions at the speed of insight
Faster time to insight
More accurate, complete dataMore effective use of resources
Lower TCO | Increase productivityMinimize business risk
Increase business agilityBuilt and supported by the creators of Trino
Learn moreGet started with Starburst
Install anywhere
Starburst includes everything you need to install and run Trino on a single machine, a cluster of machines, or even your laptop.
Marketplace offerings
Try Starburst in your preferred marketplace




A single point of access to all your data





© Starburst Data, Inc. Starburst and Starburst Data are registered trademarks of Starburst Data, Inc. All rights reserved. Presto®, the Presto logo, Delta Lake, and the Delta Lake logo are trademarks of LF Projects, LLC