
Karol Sobczak, Co-founder and Software Engineer at Starburst
Welcome back to the series of blog posts (checkout our previous post!) about Presto’s first Cost-Based Optimizer! Today let’s focus on the challenge of choosing the optimal join order. The order by which relations are joined affects performance of a query substantially. Poor join order might introduce unnecessary CPU and network overhead. To overcome that, the Starburst Presto release includes a state-of-the art join enumeration algorithm that will greatly benefit its users. Let’s first do a quick introduction how Presto join enumerator will speed up your common queries and then we will discuss the algorithm in more details.
Query improvements
Incorporating join enumeration into Presto means that your queries can automatically run faster without manual adjustments. Such manual adjustments are often not possible at all because they are not expressible in SQL language (e.g: join distribution type selection).
The only prerequisite is that your data source needs to have statistics collected (currently the Hive connector is the only connector that provides statistics).
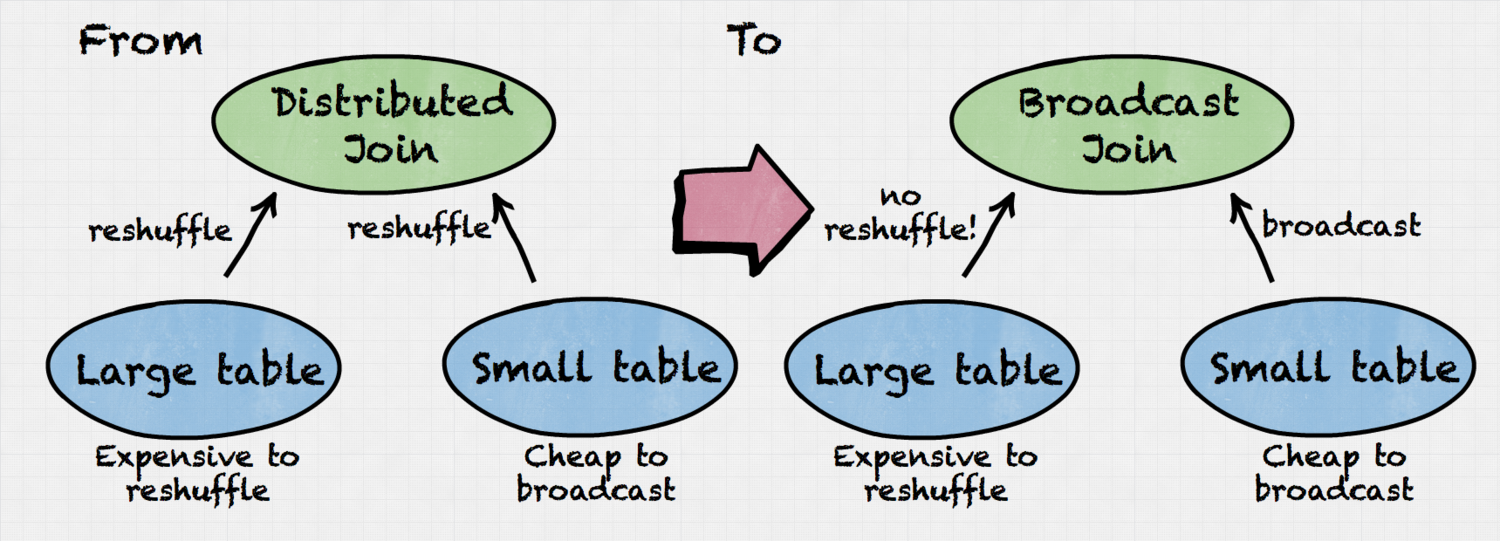
Case 1: Broadcast vs distributed
Query: SELECT * FROM large_table l, small_table s WHERE l.key = s.key
The example below shows how our algorithm selects join operator type (distributed vs broadcast) based on table sizes and cost model.
Case 2: Join sides reordering
Query: SELECT * FROM small_table s, large_table l WHERE s.key = l.key
This example displays how the algorithm flips join sides so that the table with smaller memory footprint is kept in distributed join operator.
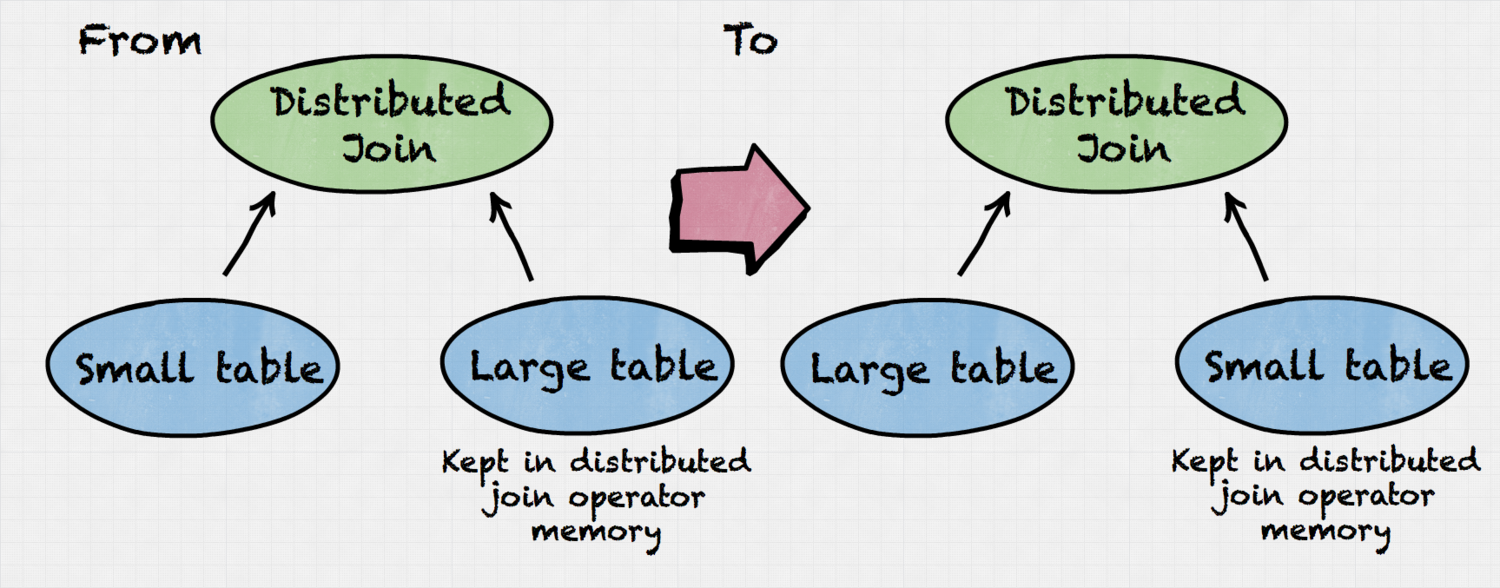
Case 3: Join tree reordering
Query: SELECT * FROM table_a a, table_b b, table_c c WHERE a.key=b.key AND a.key=c.key
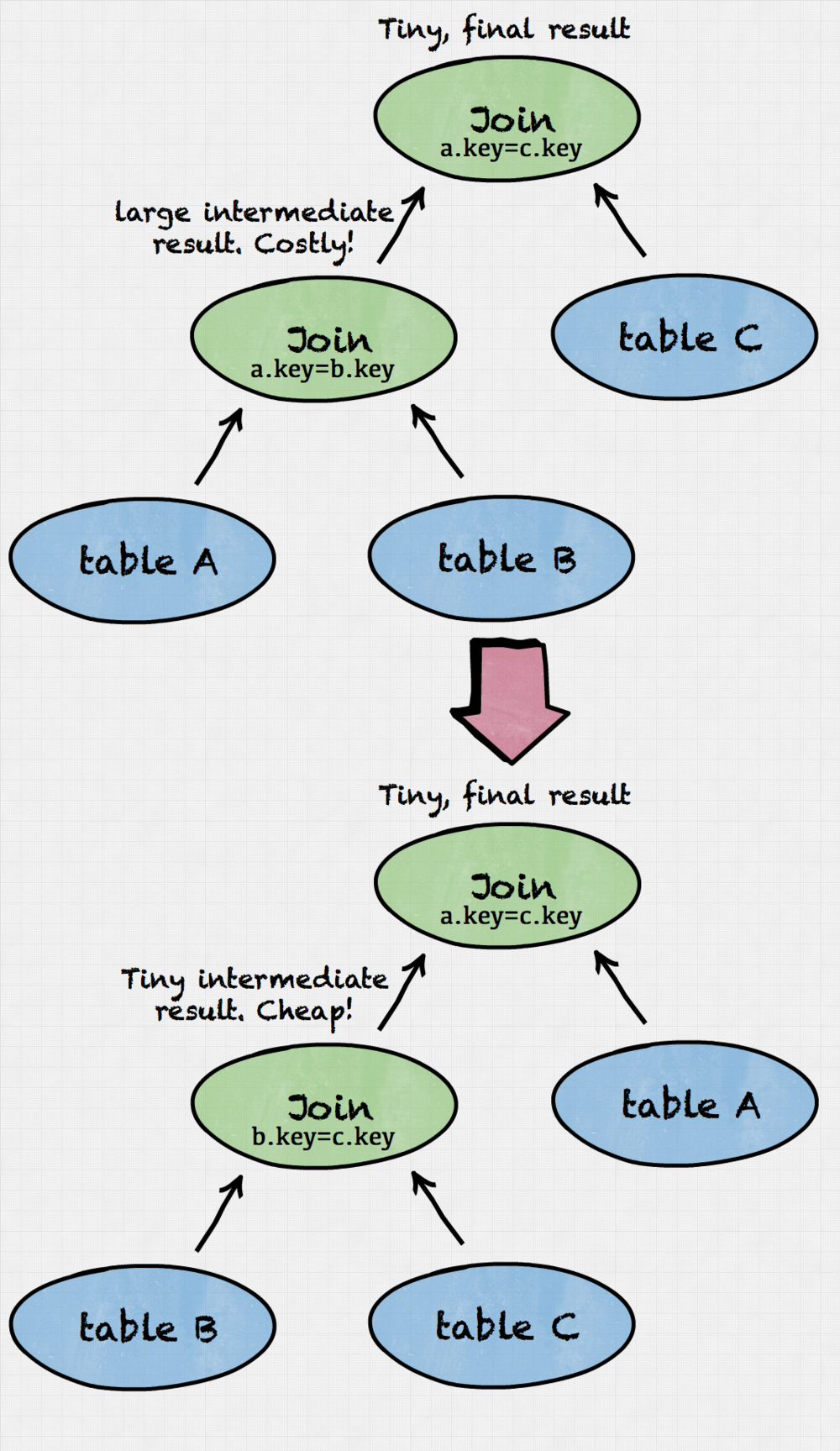
This is more complex example. In this case join enumeration algorithm will reorder the entire join tree to avoid large and costly intermediate result. It also shows that our algorithm can intelligently derive new predicates (“b.key=c.key“) so that new joins can be explored.
Join enumeration
Join enumeration is the process of enumerating and evaluating different join orders with the goal of finding an optimal execution plan. To do this efficiently, Presto join enumerator utilizes dynamic programming and divide-and-conquer technique. Such algorithms split larger problems into smaller ones. For instance, they assume that the best way to join tables (a,b,c) with table d involves finding the best join order for tables (a,b,c) first. This assumption allows to reuse join enumeration result for (a,b,c) in all join enumerations that have (a,b,c) as a subcomponent, e.g: (a,b,c,d) or (a,b,c,e).
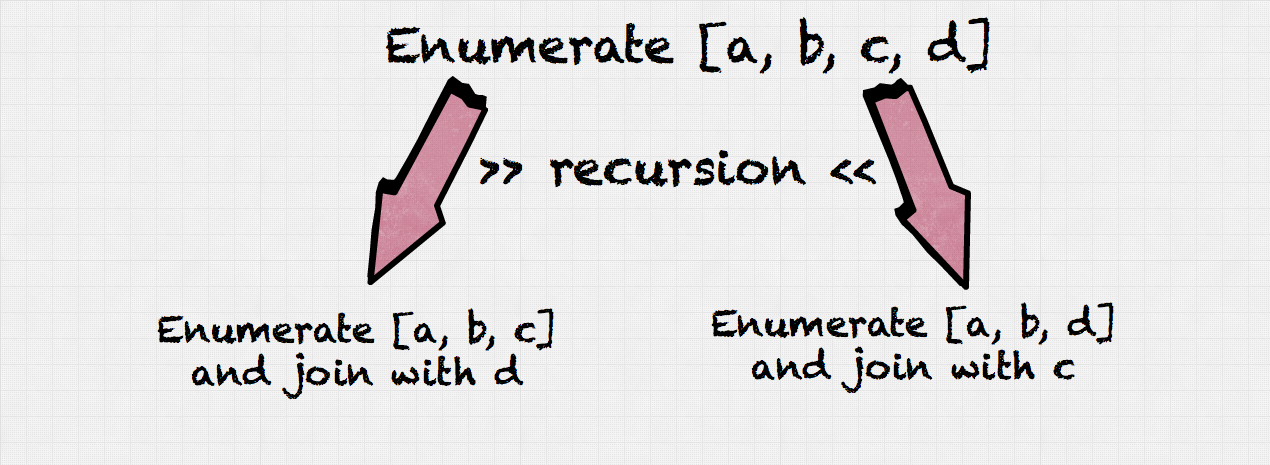
Top-down approach
Dynamic programming is usually implemented using a top-down (recursive) or bottom-up (iterative) approach. Presto join enumerator uses the former technique. In the top-down approach relation sets (i.e. tables) are partitioned into two partitions. For each partition the best join ordering is found recursively. Then the partitioning with the lowest total cost is selected as a global result. Memoization is used in order to reduce the search time.
Search space
Most optimizers (Presto included) skip cross-joins during join enumeration. It’s a good heuristic that drastically reduces the search space. Cross-joins are usually not part of an optimal join ordering and enumerating them greatly slows down query optimization process.
Some optimizers only consider left-deep join trees. This reduces search space, but could lead to suboptimal plans. We have found that the cost of exploring bushy-tree joins for a relatively small number of relations does not bring a significant overhead. Therefore, in order to to find the best plan Presto join enumerator explores both left-deep and bushy tree joins.
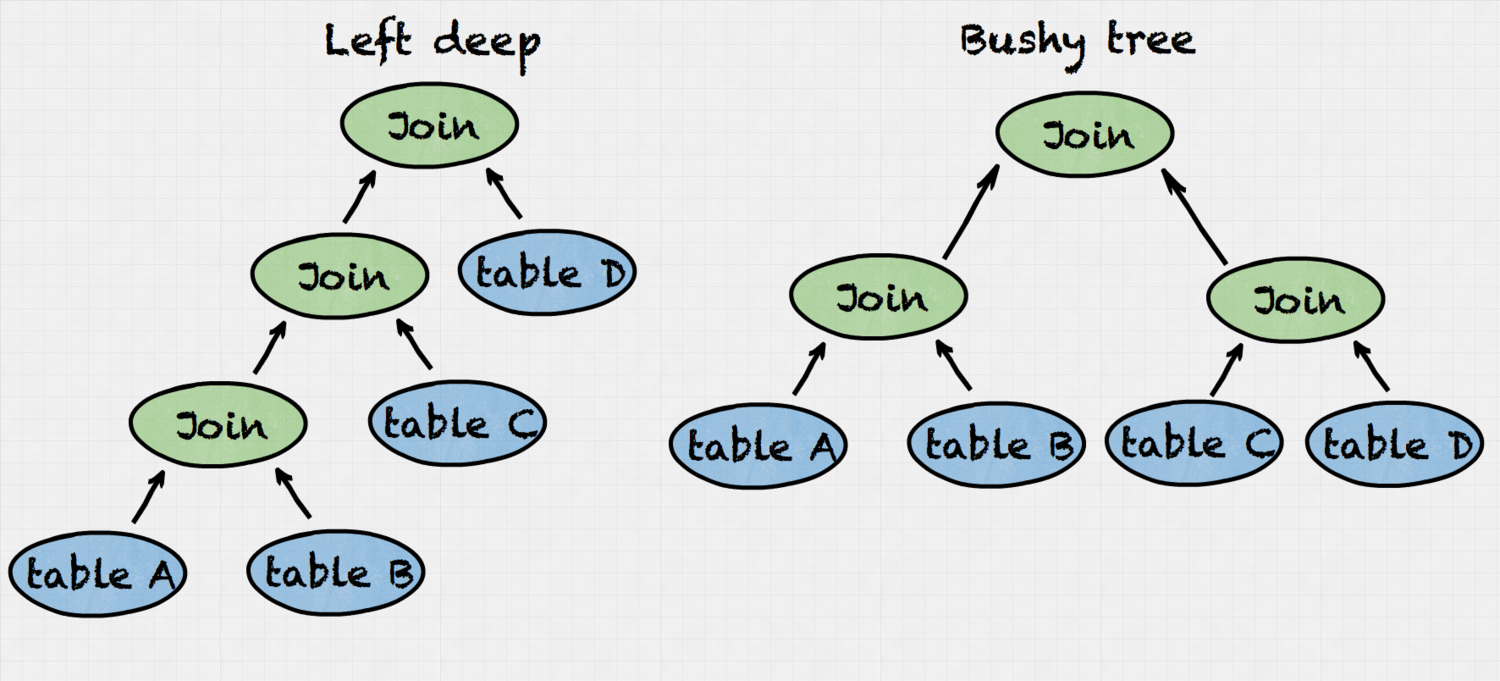
Presto algorithm design
Presto join enumeration works in the following stages:
1) First, join nodes that can be reordered are collected into a special multi-join node. Multi-join node contains aggregated information about reorderable joins. This includes source relations and predicates from all joins. It’s worth noting that for result correctness, not all joins are freely reorderable so are not collected into the multi-join node. We won’t go into those details today.
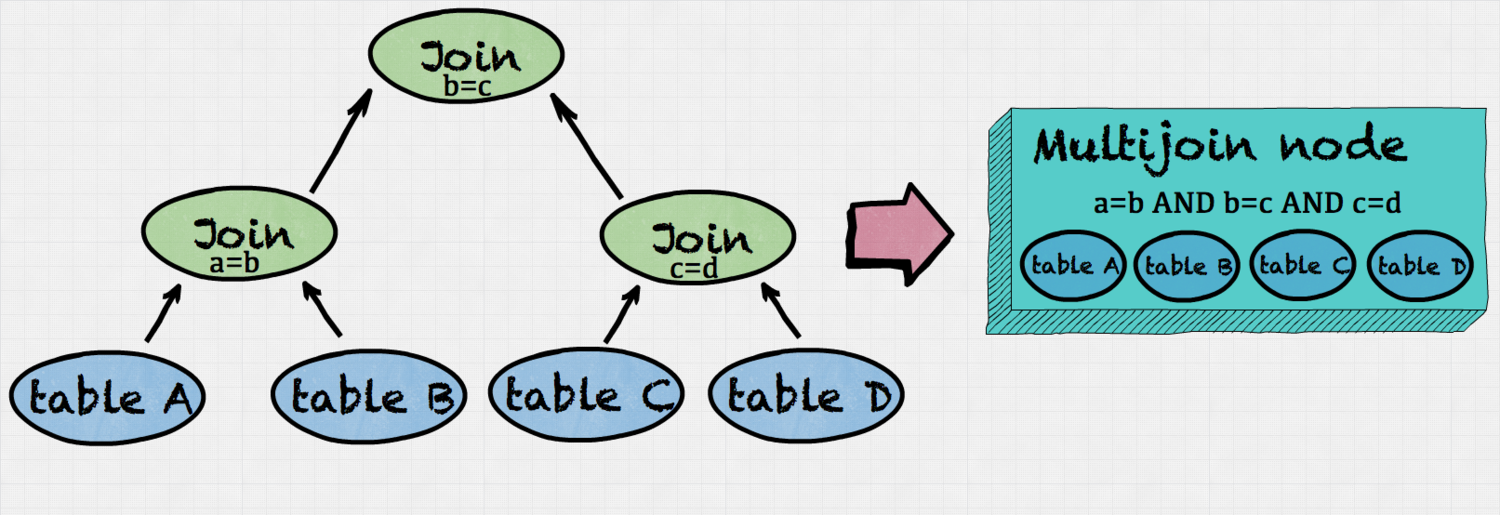
2a) Then, the best join ordering is found recursively. The procedure is as follows. For a given relation set RS find all partitionings into two partitions. We only consider partitionings where there is a join predicate between the relations (i.e. no cross joins).. For each partition the best join ordering is then found recursively.
2b) For each partitioning construct a join J between the two partitions. Consider different physical properties of a join (e.g. distributed vs. broadcast). Choose the properties with the lowest cost.
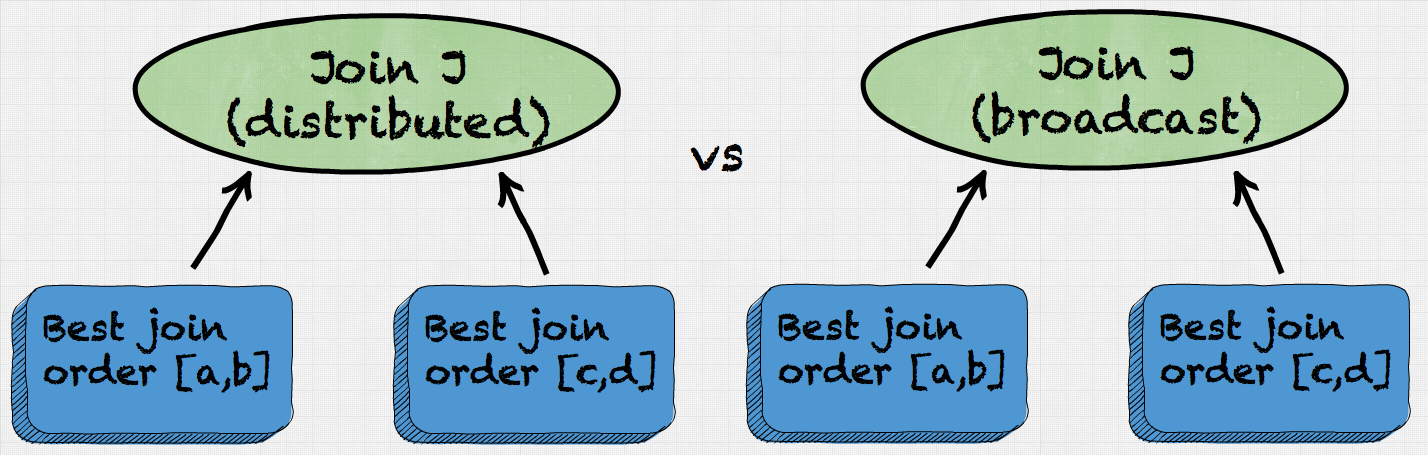
2c) Choose a partitioning with the lowest total cost. Corresponding join J is then memorized along with a total cost and a set of relations that are joined together, e.g: (a,b,c). Every time join enumeration will try to resolve best join ordering for (a,b,c) it can reuse an already computed result.
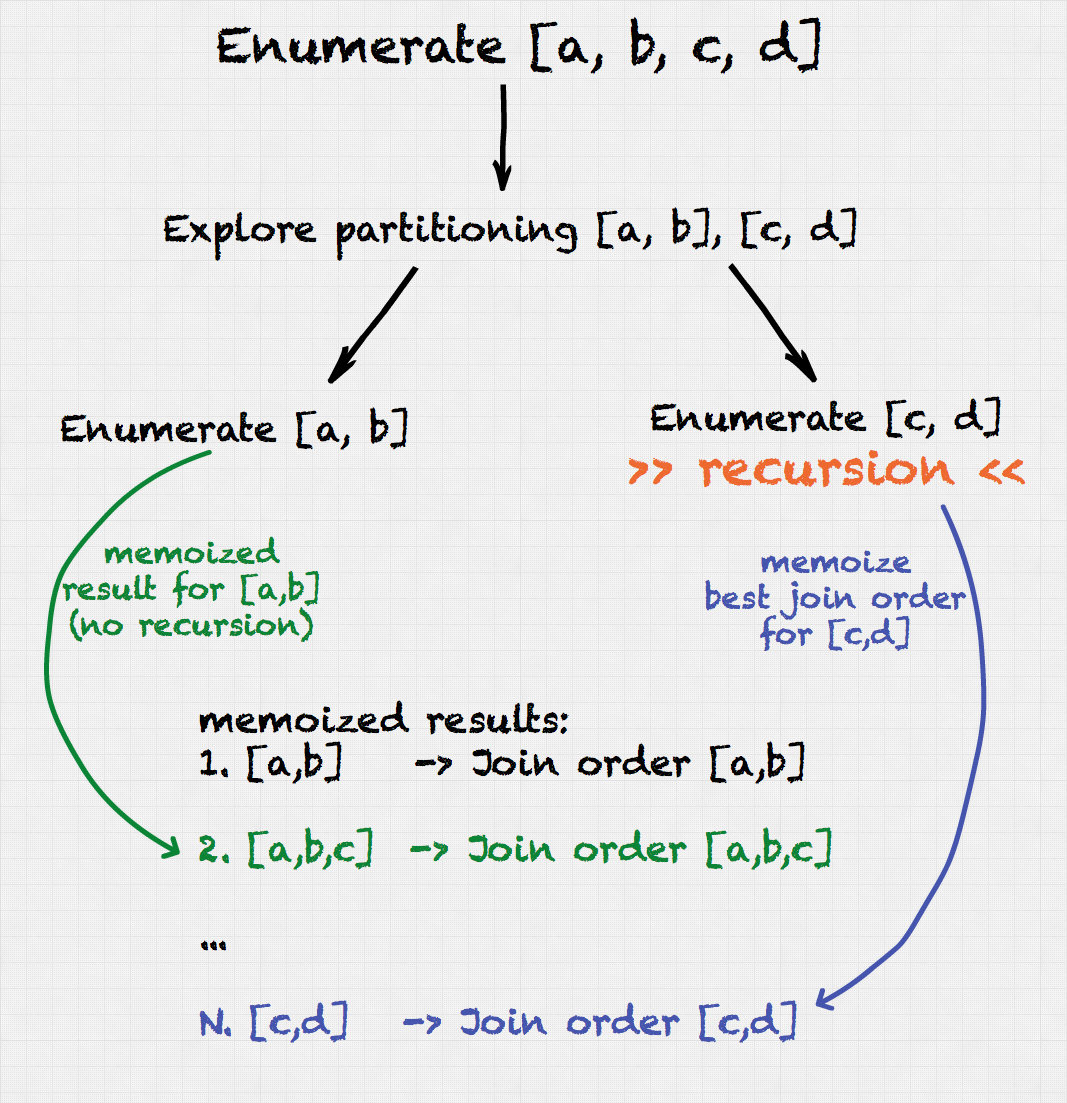
An interesting feature of our algorithm is that we derive equality predicates for joins using a so called equality inference algorithm. The input of the algorithm are predicates of all reorderable joins. The algorithm can deduce new predicates for relations that didn’t have predicates between them initially. More on that later.
Acknowledgements
This is a feature we’ve been working on for a while going back to our time at Teradata before Starburst. We’d like to give very special acknowledgement to Rebecca Schlussel currently at Facebook. Rebecca was a key engineer in the design and development of the join enumeration algorithm feature.




