
For the last few years, the hot topic in any organization is the separation of storage and compute. With data volumes increasing on a daily basis as well as the types of data being stored, placing this data on a flexible storage medium such as HDFS and cloud object storage such as Amazon’s S3 and Azure’s Blob storage provides a company with great flexibility on when and where they consume this data.
Another benefit of separating storage and compute is the reduction of data duplication. For years in the data warehouse world, we’ve been told the reason to build a warehouse is to have a “single source of the truth”. From there, data marts are built for different departments which most often duplicate the same data in the main data warehouse.
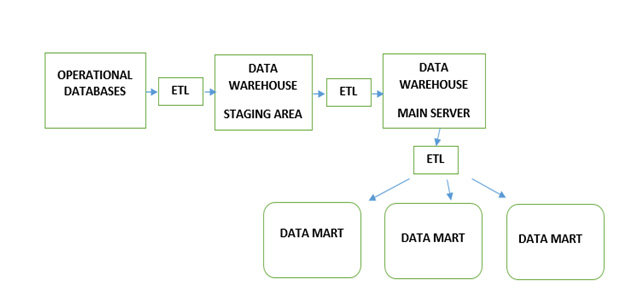
In the image above, data is first moved into the data warehouse then data is copied into data marts which are on separate database systems. Some of the problems with this “data sprawl” are:
- Cost — The above image requires 3 different database systems which of course is not only expensive from the purchase of the software/hardware but the personnel it takes to operate this complex environment.
- Data Duplication — the whole reason you created a data warehouse is to provide a single source e of truth but often users want the raw data or in a different format so now you are making copies of that data into other systems and you can no longer guarantee what a user is viewing is correct.
- Data Latency — In the above image, moving data from system to system takes time and although real-time and streaming data have made huge improvements, it still alludes the average company and end users suffer with data that is stale and possible incorrect.
The above scenario can be solved by creating a single place for all of the data and allowing different users/departments to consume that data as they wish. They will always be getting the latest version and they would be able to scale their resources up and down as needed. That is the REAL POWER OF THE CLOUD.
Below is an image which illustrates an example of a TRUE separation storage and compute architecture. This applies to on-premises, in the cloud or even in your basement.
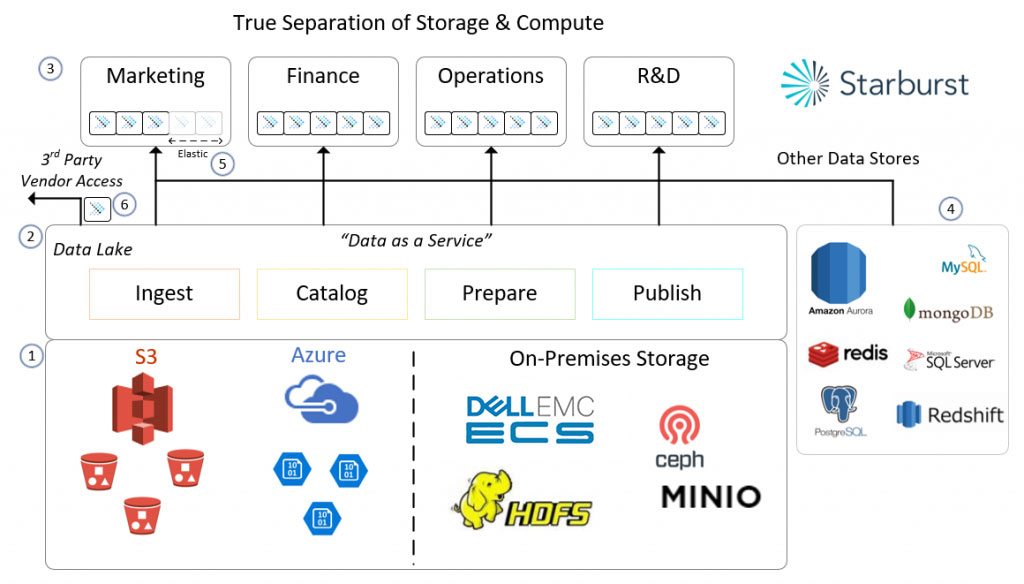
Each section is numbered and I’ll explain each one.
- With the proliferation of low cost storage in the cloud and on-premises, building your own “data lake” is now easier than ever. If you are in the cloud, both AWS and Azure offer very low cost, highly available object storage. If you are on-premises, there is always the trusted HDFS and new object store players such as Dell ECS, Minio, and Ceph.
- Ingesting, cataloging, preparing and publishing this data can be accomplished using a variety of tools such as Spark, Talend, Informatica and Python. Some people call this “data as a service” and it allows data to reside in one organized place.
- With Trino, different departments can “spin” up query clusters permanently or on demand. This removes some of the bottlenecks that data consumers experience today. Having full access to the data without having to “share” with other departments or determine who is going to pay for what is a drastic change in data analytics.
- Unlike other query engines, Trino can query beyond just HDFS and object stores. It easily connects to a wide range of systems using connectors. This list continues to grow with Trino adding even more connectors.
- If you are located in the cloud or within a private cloud, you can elastically add/remove nodes from the Trino cluster based upon demand. If one department only needs access during business hours, they can set their Trino cluster to power down at 6pm and during the weekends to save money.
- Lastly, with the agility of a separate storage location, access to certain parts of the data lake can be provided to 3rd party vendors. They can transfer the data or spin up their own Trino cluster and consume your data as they wish. This is all with just a few clicks of a mouse.
Starburst is unlike any other technology and it shows by more and more companies relying on it in their production systems both in the cloud and on-premises.
Starburst is the only company that provides Enterprise support for Trino(formerly PrestoSQL) as well as our own distribution which has the latest features and performance improvements.
Contact us today to learn more about this exciting technology and how you can use it to realize true separation of storage and compute!
Read this great Datanami blog post on the Separation of Compute and Storage as it covers some of the same subjects in this blog post and more!




