
Karol Sobczak & Anu Sudarsan, Co-Founders & Software Engineers at Starburst
Introduction
Last week, we announced the availability of Starburst’s Presto on AWS Marketplace. With this offering, one can deploy a Presto cluster and begin querying S3 data in a matter of minutes! Coupled with simple deployment, Presto is automatically configured for your AWS EC2 instances, ultimately saving you both time and AWS costs. Previously, Presto was only available on AWS via EMR; in this blog post, we’ll dive into the performance benchmark comparisons between Starburst’s Presto on AWS and AWS EMR Presto.
{{cta(‘eddbc327-0144-4f85-b4b2-4ce80ebaeed1′,’justifycenter’)}}
Starburst Presto Auto Configuration
Starburst Presto is automatically configured for the selected EC2 instance type, and the default configuration is well balanced for mixed use cases. For example, Presto may get around 80% of total node physical memory, while query.max-memory-per-node is set at a reasonable 20% of Presto Java heap memory. A configuration such as this is suitable for low-to-medium concurrency while still allowing larger single queries to pass. In a future post, we will cover more detailed auto configuration choices tailored to specific cluster use cases.
Benchmark Environment
We conducted benchmarks against TPC Benchmark™ DS (TPC-DS) schemas ranging from 10GB to 1TB. Schemas were chosen to prevent time-consuming queries, as each query was run repetitively in order to produce stable results. Additionally, the tables were stored in S3 in ORC data format (Zlib compressed) and were neither bucketed nor partitioned.
Starburst Presto was deployed using the CloudFormation template and Presto AMI from Starburst’s Presto on AWS offering. We used one coordinator and ten worker nodes, both of r4.8xlarge EC2 instance types. EMR Presto (version 0.194) from the EMR release emr-5.13.0, also used the same instance types with one Master and ten Core (worker) nodes. For cost-effectiveness, we used spot instances for both clusters. Further, we implemented a common external Hive metastore hosted in the same region as the cluster. The test result is the mean duration from six query executions after five prewarm query runs.
Results
Overall, Starburst Presto performs much better than EMR Presto on the same instance types; and our results have shown that said performance is better both with and without the cost based optimizer enabled. Additionally, EMR Presto fails to complete all TPC-DS queries out of the box.
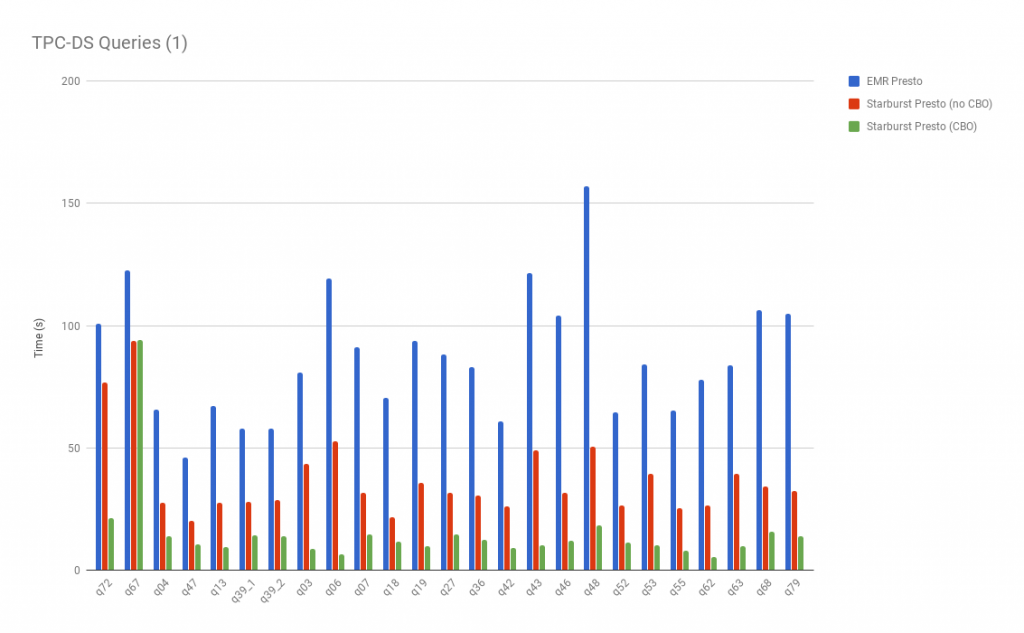
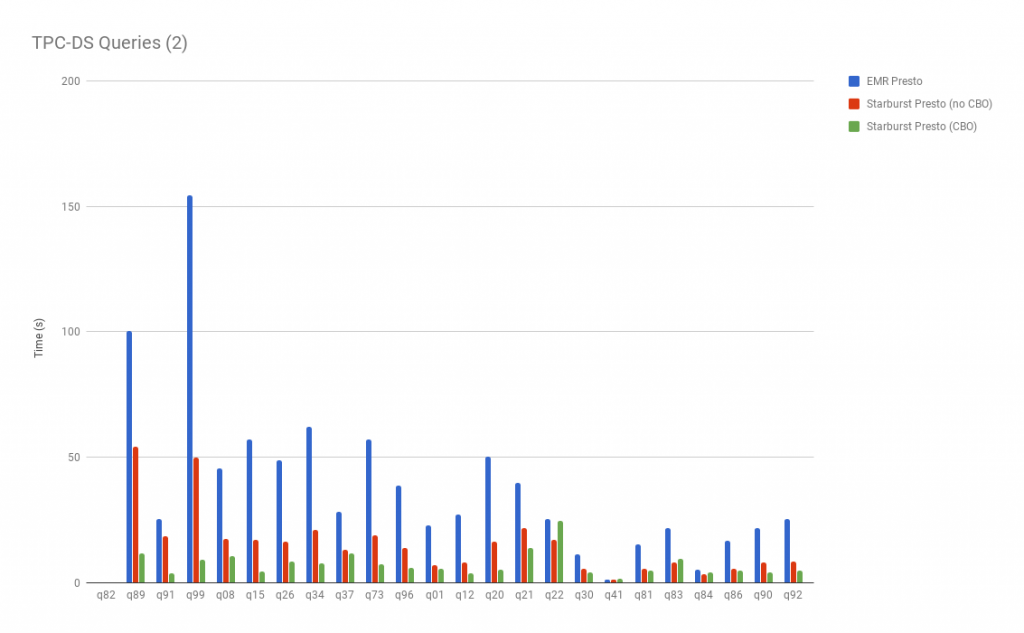
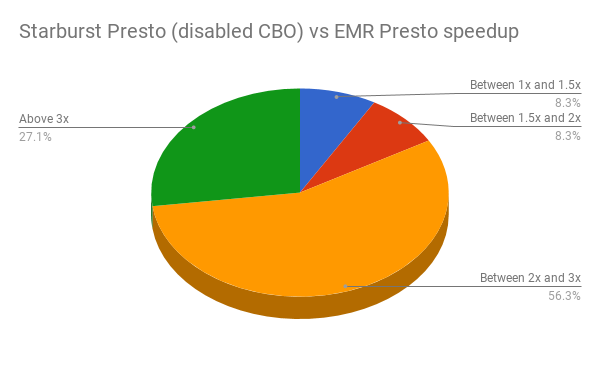
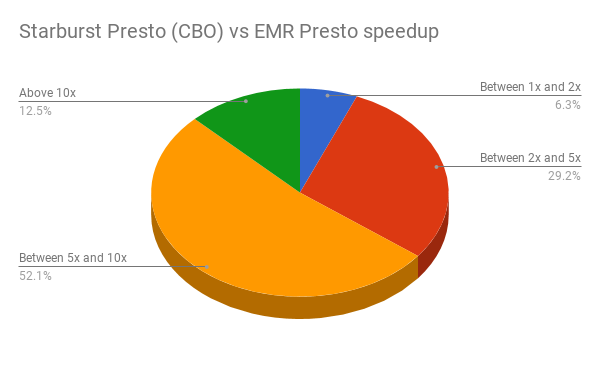
Thus for running the entire benchmark queries reported here, Starburst Presto gave us around 7x improvement in terms of AWS cluster cost as compared to EMR Presto. The above graphs clearly illustrate the performance gains for Starburst Presto– showing the largest when CBO is used. Here are speedup charts which provide a more aggregated improvements summary:
EMR Presto Tuning
With default EMR Presto configuration, more than 52% of queries failed in the benchmark.
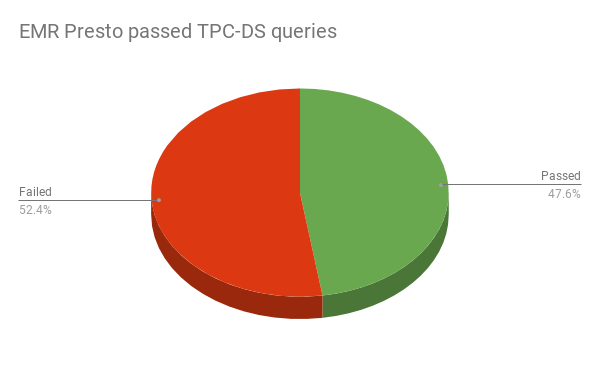
The majority of the queries failed due to the “Queries exceeded max memory size..” error. In an effort to correct this issue, we modified query.max-memory property in EMR Presto. Above this, we also tuned fs.s3.maxConnections property in EMRFS to fix timeout in queries. Although queries started passing, these efforts did not bring any significant improvement to query performance. We also switched EMR Presto not to use EMRFS, but use PRESTO as the hive.s3-file-system-type to study any benefits of the file system type. However, we did not observe any significant change in query runtime. The numbers reported above are the best we received from EMR Presto after multiple tuning attempts.
Conclusions
Overall, because of the improvement in query execution times, our Starburst Presto release enables one to run more analytics and/or reduces your AWS costs. Additionally, our release is much easier to use, as it works seamlessly with your S3 data. On the other hand, our experience with EMR Presto was on the opposite end of the spectrum. Over 52% out of 99 TPCD-S queries fail out of the box, and we had to expend considerable effort and research in debugging and figuring out why EMR Presto doesn’t work as well as our distribution.
Future posts
In the future, we plan to release a blog focused on the process of choosing an instance type depending on cluster workload. Choosing the right, and most cost-effective, instance type is a difficult task and deserves separate consideration.
Try Presto on AWS Today!
Need help with getting setup or want to learn more? Contact us aws@starburstdata.com




